
Today we covered what felt like a huge amount of content; well done for a busy lesson. I'll list all the resources below:
I gave out research methods booklets, here is an electronic version, please bring these every lesson. The plan is to start every lesson with 15 minutes RM.
I also handed out a schedule for the whole term. Here is a copy.
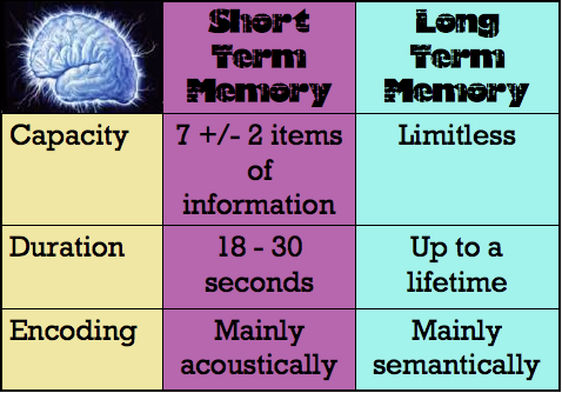
We covered duration in LTM; we discussed children's TV programmes and the difference between recall and recognition. We looked at Bahrick's study, which found good evidence for the duration of long-term memories. Recognition (cue provided) was better than recall. Here is the duration in LTM powerpoint.
We then looked at capacity in STM. We measure our average digit span to be around 7.2 items. Miller defined STM capacity as being 7 plus or minus 2, and looked at the idea of chunking. We discussed postcodes and telephone numbers as real life applications of chunking. Remember that chunking isn't wholly foolproof; the size of the chunk does matter (Simon, 1974). Here is the capacity powerpoint.
Finally we discussed encoding in STM and LTM. We replicated the Baddeley (1966) study. For STM, participants did worse in the acoustic similarity category. Baddeley concluded that this meant that the brain codes acoustically in STM. This is a crucial point! If you don't follow, please ask next lesson. For LTM, people performed worse in the semantic similarity category, showing that this is how the brain codes in long-term memory. Here is the encoding powerpoint.
No comments:
Post a Comment